Performance marketing is a skill every startup should hone as a core competency as quickly as possible. Performance marketing creates a process where $1 invested in the business creates greater than $1 in output - a growth machine.
Building a growth engine
The goal of performance marketing is simple: to determine, as precisely as possible, the expected value of every current and potential user. This data enables the marketing team to know exactly how much they should be willing to pay to acquire the user. Or how much to incent a current user to upgrade. Or pursue some other action like invite a friend or share a tweet.
The expected value of a customer changes dynamically as a function of the amount and kind of data a startup can collect about a user. The more data, the better the expected value prediction.
The challenge, of course, is building the system to calculate a user’s expected value. Problems like these are perfect for statistical analysis and machine learning. Because engineering is often the limiting factor in most startups, and new features or bug fixes are top priority, engineering marketing solutions is often under-prioritized.
But building a simple generalized linear model isn’t incredibly complex. It can be done in three steps in R, as I’ve been learning over the past few weeks.
First, gather the data
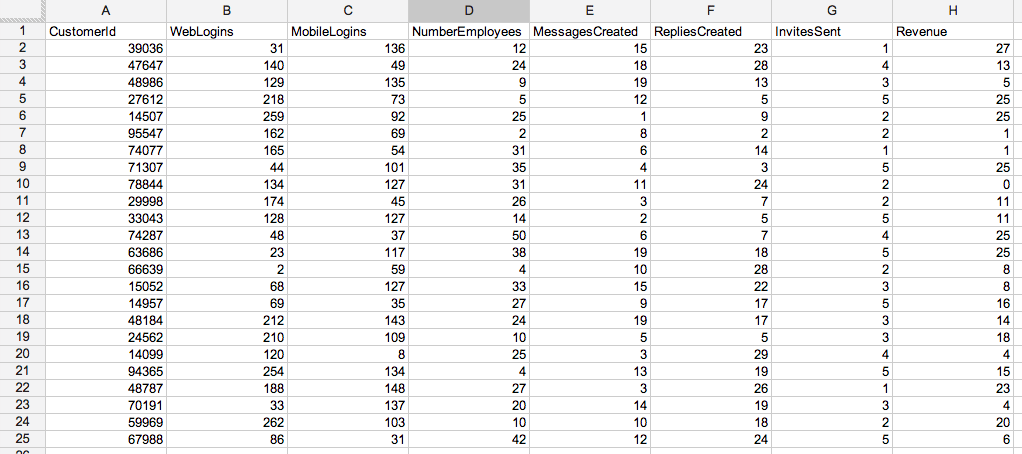
To create a model, we need to create a spreadsheet of customer behavior and data by column and save it as a csv. Here is a Google Doc of random data that might serve as a good start for a SMB SaaS company building a Yammer competitor.
Second, create a linear model in R
After installing and configuring R, building a model is trivial. It takes three lines of code.
ac <- read.csv("~/marketing/accountCohort.csv") #load the data
lm.ac = lm(formula = Revenue ~ ., data = ac[,2:7]) #build a model to predict revenue
summary(lm.ac) #spits out the performance data of the model
The first line ingests the data into R. The second line creates a basic multivariate linear model to predict the Revenue column using the six other variables. And the third spits out summary stats.
Third, evaluate the model
I’ve copied a sample set of summary statistics below. The most important single number is in the second to last line: the Adjusted R-Squared which is 0.909 in this case. This number indicates the percent of variability my model predicts. Rule of thumb: this number needs to be above 0.9 to be a good predictor of revenue. This model clearly is a good predictor, explaining 91% of the variance.
The data in the coefficients table indicates which variables are good predictors of revenue with the number of asterixes at the end of the line. In this case Replies Created and Mobile Logins are terrible predictors. But all the others are quite good.
Call:
lm(formula = Revenue ~ ., data = ac[, 1:15])
Residuals:
Min 1Q Median 3Q Max
-74.682 -0.020 0.018 0.018 32.994
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -5.307e-04 1.229e-02 -0.043 0.96555
WebLogins 1.734e-01 4.868e-04 356.165 < 2e-16 ***
MobileLogins 1.329e-04 2.610e-04 0.509 0.61067
NumberEmployees -7.449e-02 1.571e-02 -4.742 2.14e-06 ***
MessagesCreated 3.862e-02 5.976e-03 6.463 1.05e-10 ***
RepliesCreated -4.881e-04 4.527e-03 -0.108 0.91414
Invites Sent -2.499e-01 4.238e-03 -58.966 < 2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.916 on 18227 degrees of freedom
Multiple R-squared: 0.909, Adjusted R-squared: 0.909
F-statistic: 1.518e+04 on 12 and 18227 DF, p-value: < 2.2e-16
Rinse, Lather, Tune and Repeat
It’s not often that a model is this strong the first time it is run (phony data helps).
In fact, the challenging part in modeling isn’t actually telling the computer to build the model. Instead, it’s finding the features (the columns of data) that accurately predict customer value. If my model hadn’t worked, I would have needed to add other data to the csv and run the model again.
With a tuned model, it’s possible to predict the value of a given user (or millions of users) with one line of code, R’s predict function.
Once we know the revenue potential of a user, we know how much we might be willing to pay to incent the user to perform certain actions. And we have built a framework for performance marketing.