Ten months ago, DeepSeek collapsed AI training costs by 90% using distillation - transferring knowledge from larger models to smaller ones at a fraction of the cost.
Distillation works like a tutor training a student : a large model teaches a smaller one.1 As we’ve shifted from knowledge retrieval to agentic systems, we wondered if there was a parallel technique for tool calling.2
Could a large model teach a smaller one to call the right tools?
The answer is yes, or at least yes in our case. Here’s our current effort :
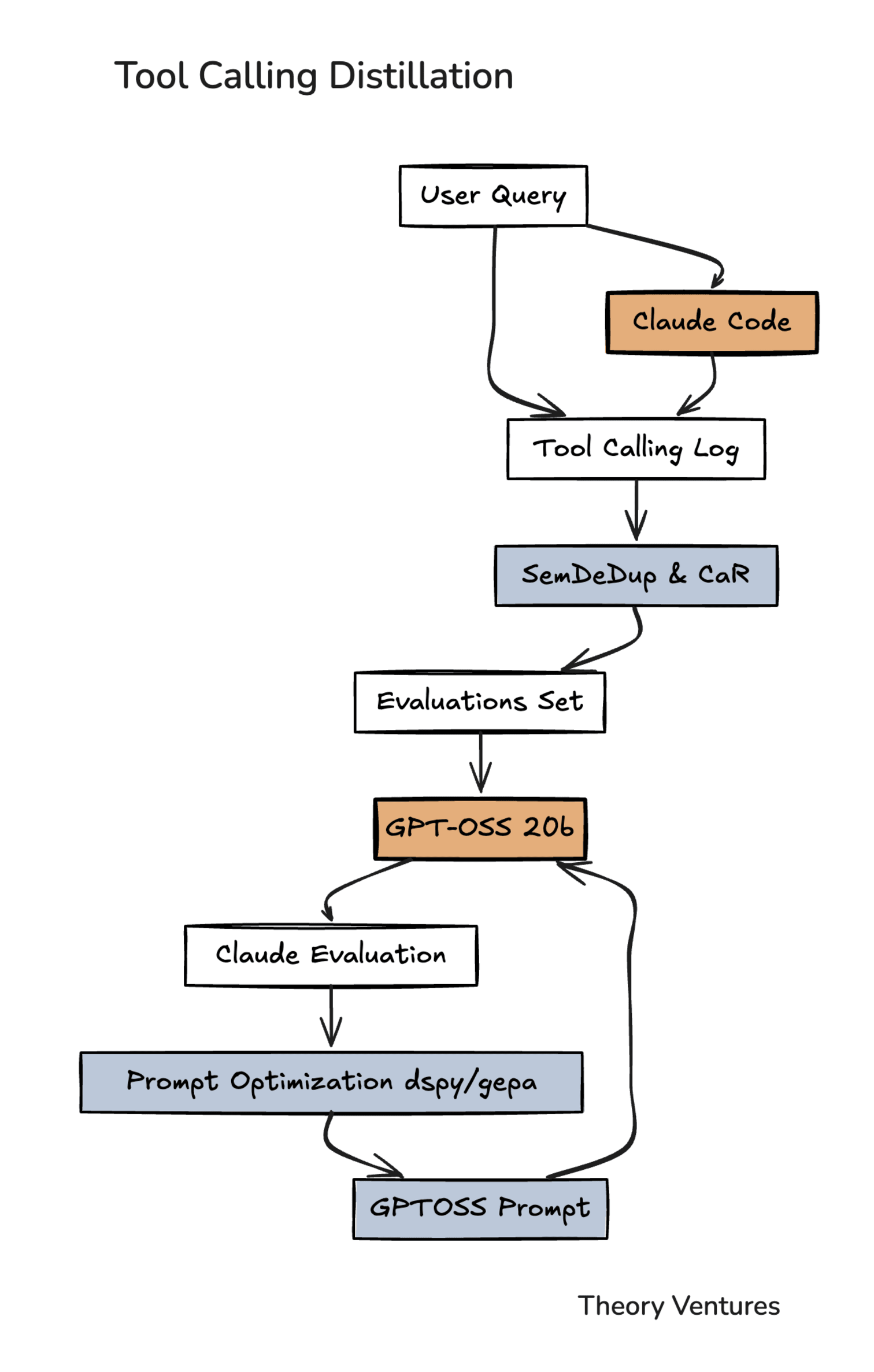
Every time we used Claude Code, we logged the session - our query, available tools, & which tools Claude chose. These logs became training examples showing the local model what good tool calling looks like.
We wanted to choose the right data so we used algorithms to cherry-pick. We used SemDeDup3 & CaR4, algorithms to find the data examples that lead to better results.
Claude Code fired up our local model powered by GPT-OSS 20b5 & peppered it with the queries. Claude graded GPT on which tools it calls.
Claude’s assessments were fed into a prompt-optimization system with DSPy6 & GEPA7. All of that data was then fed to improve the prompt. DSPy searches for existing examples that could improve the prompt, while GEPA mutates or tests different mutations.
Combined, we improved from a 12% Claude match rate to 93% in three iterations by increasing the data volume to cover different scenarios :
| Optimizer | Training Examples | % of Claude |
|---|---|---|
| DSPy Phase 1 | 50 | 12% |
| GEPA Phase 2 | 50 | 84% |
| GEPA Phase 3 | 15 (curated) | 93% |
DSPy improved accuracy from 0% to 12%, and GEPA pushed it much higher, all the way to 93%, after three phases. The local model now matches Claude’s tool call chain in 93% of cases.
Make no mistake : matching Claude 93% doesn’t mean 93% accuracy. When we benchmarked Claude itself, it only produced consistent results about 50% of the time. This is non-determinism at work.
This proof of concept works for a small set of tools written in the code mode fashion. It suggests there is a potential for tool calling distillation.
If you’ve tried something similar, I’d love to hear from you.
-
A Survey on Knowledge Distillation of Large Language Models - Xu et al. (2024) examine knowledge distillation as a methodology for transferring capabilities from proprietary LLMs like GPT-4 to open-source models like LLaMA & Mistral. The survey covers applications in model compression, efficient deployment, & resource-constrained environments, providing a comprehensive overview of distillation techniques for modern language models. ↩︎
-
ODIA: Oriented Distillation for Inline Acceleration of LLM-based Function Calling - Recent research on distilling function calling capabilities from larger models to smaller ones. ODIA leverages online user interaction data to accelerate function calling, reducing response latency by 45% (expected) & 78% (median) while maintaining accuracy. The method successfully handled 60% of traffic with negligible accuracy loss in production deployment. ↩︎
-
SemDeDup: Data-efficient learning at web-scale through semantic deduplication - Abbas et al. (2023) present a method that uses embeddings from pre-trained models to identify & remove semantic duplicates from training data. Analyzing LAION, they showed that removing 50% of semantically similar data resulted in minimal performance loss while effectively halving training time, with additional out-of-distribution performance improvements. ↩︎
-
CaR (Cluster and Retrieve) - A data selection technique that clusters similar training examples & retrieves the most representative ones to improve model performance. This method reduces redundancy in training data while preserving diversity, leading to more efficient learning. ↩︎
-
This model is sandboxed. It reads production data but doesn’t write for safety. ↩︎
-
DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines - Khattab et al. (2024) introduce DSPy, a framework that programmatically creates & refines prompts through optimization strategies that systematically simulate instruction variations & generate few-shot examples. Research across multiple use cases showed DSPy can improve task accuracy substantially, with prompt evaluation tasks rising from 46.2% to 64.0% accuracy through bootstrap learning & teleprompter algorithms. ↩︎
-
GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning - Agrawal et al. (2025) present GEPA, a reflective prompt optimizer that merges textual reflection with multi-objective evolutionary search. GEPA outperforms GRPO by 10% on average (up to 20%) while using up to 35x fewer rollouts. It surpasses the previous state-of-the-art prompt optimizer MIPROv2 on every benchmark, obtaining aggregate optimization gains of +14% compared to MIPROv2’s +7%. The system iteratively mutates prompts based on natural language feedback from execution traces. ↩︎