As demand for AI inference explodes, I’ll be asking a lot more of my little computer.
How much more?
Over the past five weeks, I’ve been using local models to see how much of my daily work I can accomplish without the trillion parameter models in the cloud. The answer is half.
| Category | Count | % of Total | Example |
|---|---|---|---|
| Other | 521 | 35.3% | Catch-all for unstructured requests |
| Scheduling | 254 | 17.2% | Check availability, propose meeting times |
| Market Research | 192 | 13.0% | Competitor analysis, fundraising data |
| Summarization | 184 | 12.4% | Transcript review, video summaries |
| Email & Inbound | 170 | 11.5% | Draft replies, follow-ups, forwards |
| Engineering | 147 | 9.9% | Debug scripts, API fixes, CLI tasks |
| Admin | 10 | 0.7% | Travel, expenses, reimbursements |
If you classify these 1.4k tasks by category, half can succeed on a local 35B model. Email & Inbound, Scheduling, Summarization, & Admin total 618 tasks (41.8%). Market Research & Engineering split roughly 50/50 between simple tasks (data lookups, script fixes) and complex ones (multi-source synthesis, architectural decisions). That gets us to 50%.
There are many reasons to use local models : privacy, cost, asset depreciation.1
But in reality, the only one that really matters is latency.
I ran a head-to-head benchmark this morning. Eight agentic tasks, same prompts, both models warmed. Qwen 3.6 35B-A3B-4bit on my MacBook Pro M5 vs Claude Opus 4.5 via API.
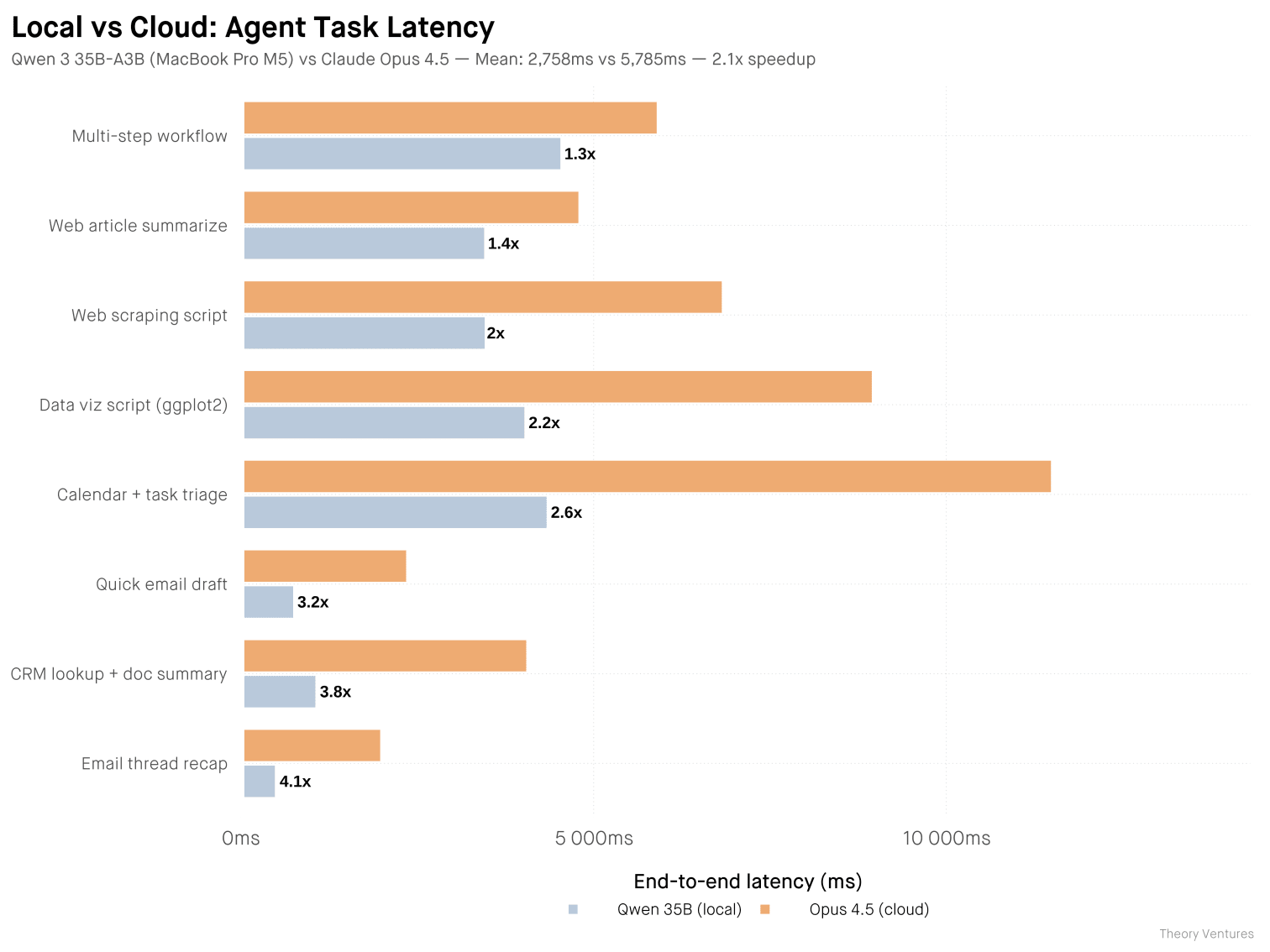
The local model isn’t smarter. Opus 4.5 scores ~20% higher on reasoning benchmarks. Local models lag frontier by 3-4 months, and for large-scale complex tasks, that gap matters. But for routine agent tasks, it rarely does.
Opus wins on structure & polish : bullet points, headers, cleaner code. Qwen wins on brevity, often half the tokens. I read every output side by side, and both completed the tasks correctly. For agent tasks where output feeds into another system, terseness is a feature.
Localmaxxing, pushing more inference to local models, is an inevitable response to tokenmaxxing. As local models improve & close the gap with frontier, more users will shift workloads to their own hardware.
If half the work runs 2x faster on my laptop, I’ll take that trade every time. My little computer is about to earn its keep.
-
A MacBook Pro depreciates whether you use it or not. Running local inference extracts compute value from a sinking asset before resale. ↩︎