As I’ve described in a previous post, this blog’s goal is to create and sustain relationships with readers across the startup landscape. Tuning the engine is proving much harder than I expected and I suspect that content marketers are facing similar issues.
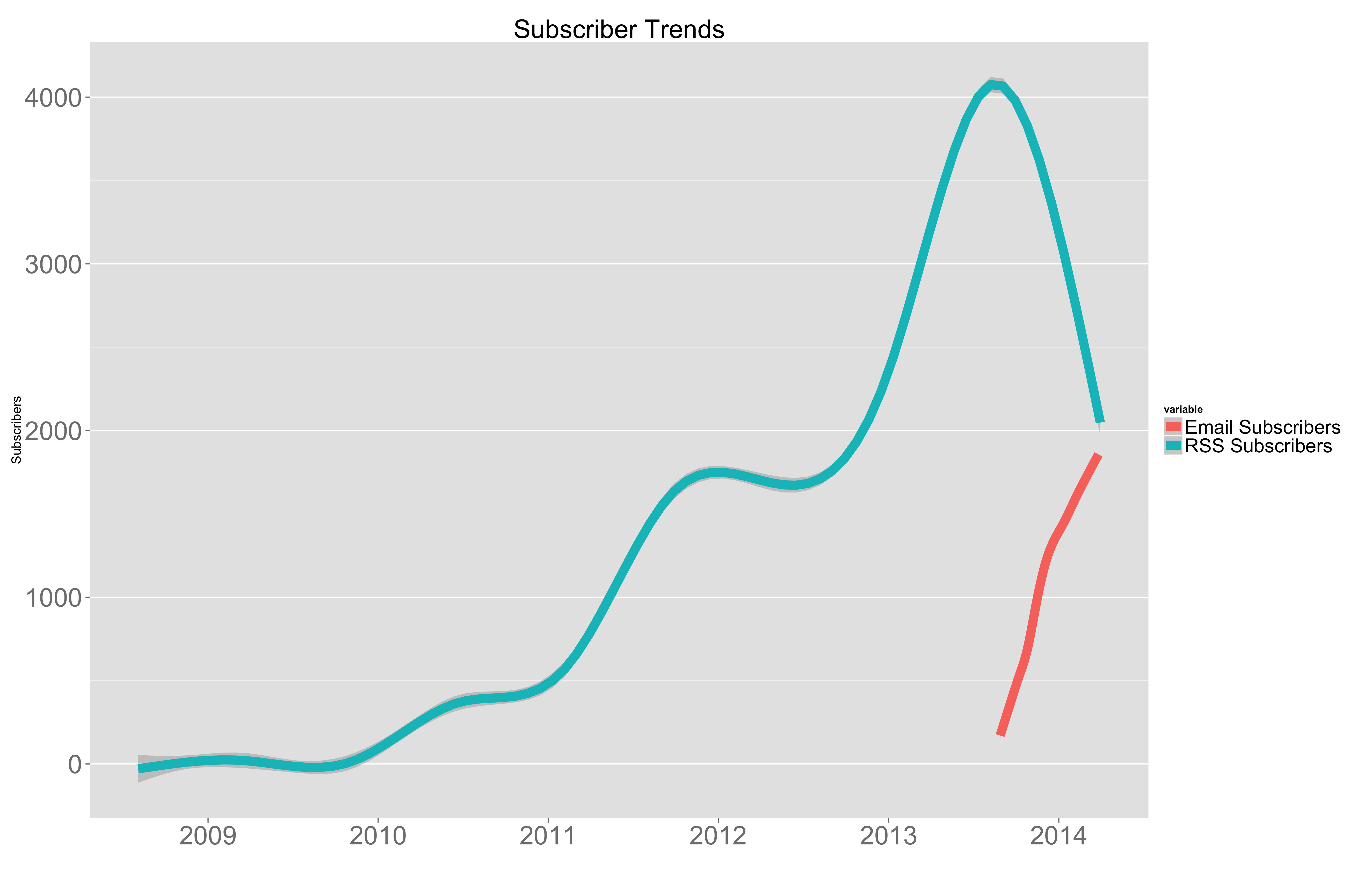
For example, over the past 18 months I’ve witnessed a halving of RSS subscribers to this blog. They have fallen from about 4,000 to about 2,000. I wasn’t sure what the cause could be, until I compared the RSS data with email subscriber data. The chart above contrasts the two data sets. Clearly, email subscriptions are cannibalizing RSS subscriptions.
Logically, the next question to ask then is how to maximize email subscribers. I wondered if the most popular posts generate more email subscribers. Surprisingly, no. Below is a table of all the blog posts bucketed by total visitors generated in quartiles. There are an equal number of blog posts sampled in the 1000-1600 visitor bucket as the 2500-25,000 visitor bucket. The table compares average new email subscribers generated, the percent of visitors those signups represent and the median new subscribers.
| Visitor Bucket | Average New Subs | Avg New Sub % | Median New Subs |
|---|---|---|---|
| 1000 | 18.6 | 2.6% | 12.0 |
| 1600 | 13.3 | 1.0% | 11 |
| 2500 | 13.7 | 0.7% | 12.0 |
| 25,000 | 12.5 | 0.2% | 8.5 |
Although the average new subs in each bucket does vary, a running a t-test proves that the averages aren’t statistically different. In other words, the number of new email subscribers to this blog seems to be independent of traffic to the post.
Through these two analyses, a few things became clear to me. First, it’s difficult to explore this data. Three different repositories store the figures needed to create this analysis: Google Analytics, FeedBurner and Mailchimp. Aggregating the data meant writing scripts to APIs and then manually cleaning and merging the data. I’d love to see the impact of comments on these metrics. But that means another API, another script and some more data cleaning.
Second, it’s easy to draw the wrong conclusions from the data. Looking only at the average new subs number, I might have concluded writing more niche content, perhaps code heavy posts with engineers in mind, would increase this blog’s readership. But the t-test disproved that hypothesis.
Third, all this work is time-intensive and for the content marketer looking to maximize daily impact, this type of analysis is cost-prohibitive on daily or even weekly basis.
Marketing is being transformed and content marketing is a key component of that transformation, but the tools to make the right decisions about how to properly market aren’t yet in place. First, the data needs to aggregated, rationalized and unified. Then, a layer of analysis and statistics must be applied. With that in place, content marketers and this blog will be much more effective in serving the needs of their audience and achieving their goals.
If you’ve seen any tools that might fit the bill, please let me know in the comments. I’d love to give them a spin on my data.