Talented people get promoted to management. So do talented models. Claude manages code execution. Gemini routes requests across CRM & chat. GPT-5 can coordinate public stock research.
Why now? Tool calling accuracy crossed a threshold. Two years ago, GPT-4 succeeded on fewer than 50% of function-calling tasks. Models hallucinated parameters, called wrong endpoints, forgot context mid-conversation. Today, SOTA models exceed 90% accuracy on function-calling benchmarks1. Performance of the most recent models, like Gemini 3, is materially better in practice than the benchmarks suggest.
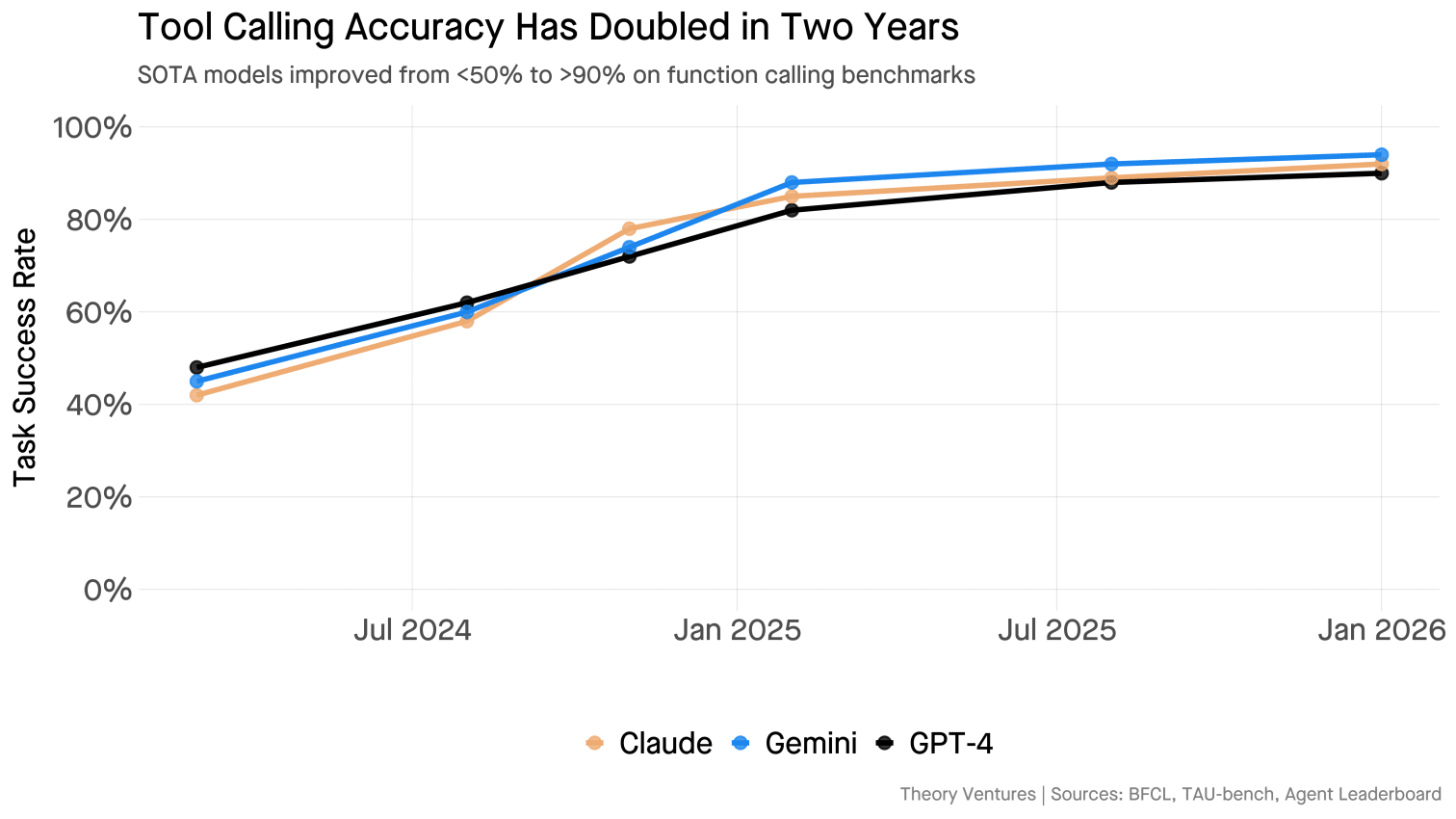
Did we need trillion-parameter models just to make function calls? Surprisingly, yes.
Experiments with small action models, lightweight networks trained only for tool selection, fail in production2. They lack world knowledge. Management, it turns out, requires context.
Today, the orchestrator often spawns itself as a subagent (Claude Code spins up another Claude Code). This symmetry won’t last.
The bitter lesson3 insists ever-larger models should handle everything. But economics push back : distillation & reinforcement fine-tuning produce models 40% smaller & 60% faster while retaining 97% of performance4.
Specialized agents from different vendors are emerging. The frontier model becomes the executive, routing requests across specialists. These specialists can be third-party vendors, all vying to be best in their domain.

Constellations of specialists require reliable tool calling. When tool calling works 50% of the time, teams build monoliths, keeping everything inside one model to minimize failure points. When it works 90% of the time, teams route to specialists & compound their capabilities.
The frontier labs will own the orchestration layer. But they can’t own every specialist. Startups that build the best browser-use agent, the best retrieval system, the best BI agent can plug into these constellations & own their niche.
New startup opportunities emerge not from training the largest models, but from training the specialists the executives call first.
-
Berkeley Function Calling Leaderboard (BFCL) tests API invocation accuracy. TAU-bench measures tool-augmented reasoning in real-world scenarios (paper). ↩︎
-
Salesforce’s xLAM is a large action model designed specifically for tool selection. While fast & accurate for simple tool calls, small action models struggle with complex reasoning about when to use tools. ↩︎
-
Rich Sutton’s influential essay arguing that general methods leveraging computation beat hand-engineered domain knowledge. The Bitter Lesson. ↩︎
-
See DistilBERT, which is 40% smaller & 60% faster while retaining 97% of BERT’s performance. OpenAI’s model distillation enables similar efficiency gains. ↩︎