In the past, the bigger the AI model, the better the performance. Across OpenAI’s models for example, parameters have grown by 1000x+ & performance has nearly tripled.
| OpenAI Model | Release Date | Parameters, B | MMLU |
|---|---|---|---|
| GPT2 | 2/14/19 | 1.5 | 0.324 |
| GPT3 | 6/11/20 | 175 | 0.539 |
| GPT3.5 | 3/15/22 | 175 | 0.7 |
| GPT4 | 3/14/23 | 1760 | 0.864 |
But model performance will soon asymptote - at least on this metric.
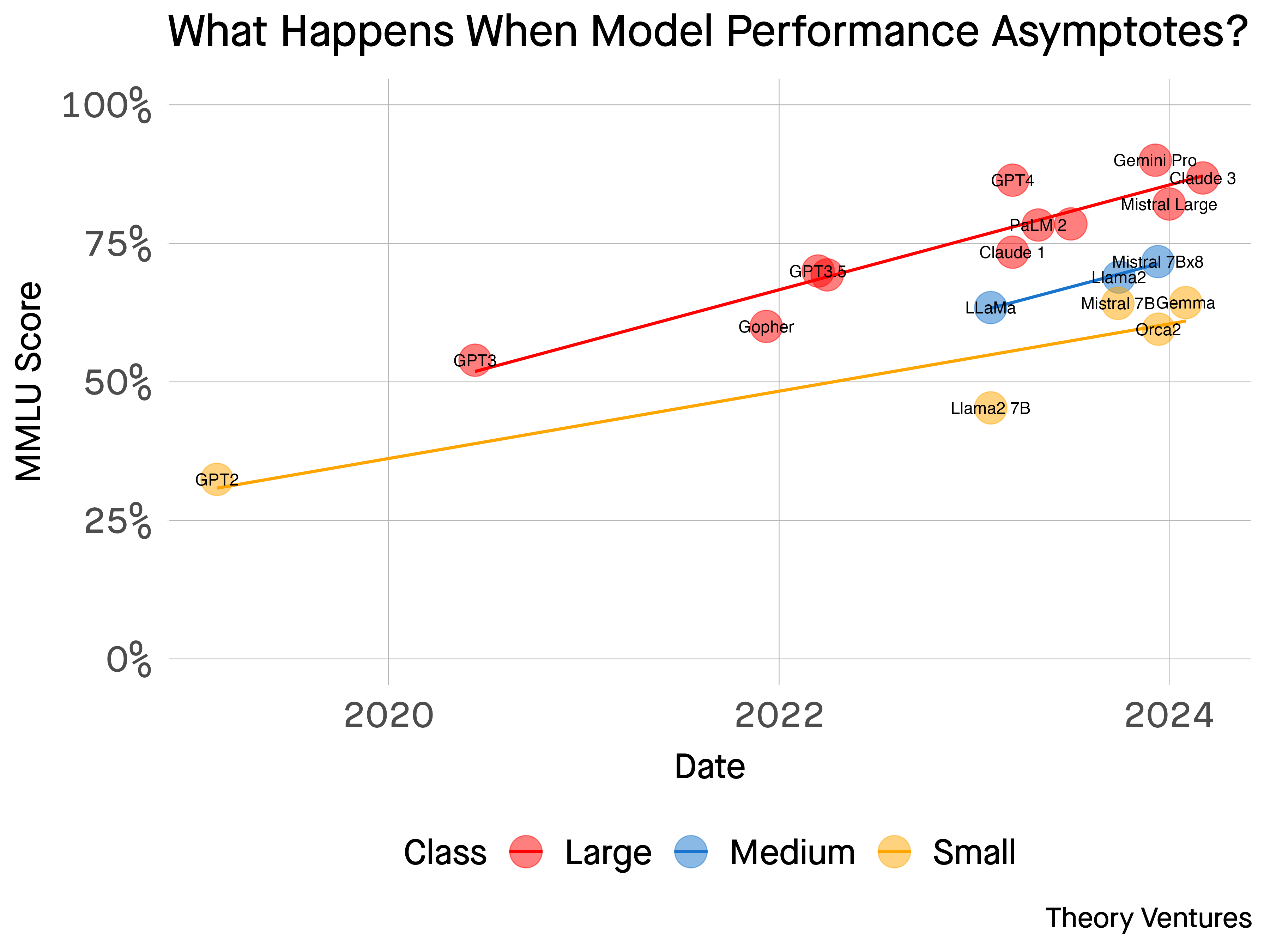
This is a chart of many recent AI models’ performance according to a broadly accepted benchmark called MMLU. 1 MMLU measures the performance of an AI model compared to a high school student.
I’ve categorized the models this way :
- Large : > 100 billion parameters
- Medium : 15 to 100b parameters
- Small : < 15b parameters
Over time, the performance is converging rapidly both across model sizes & across the model vendors.
What happens when Facebook’s open-source model & Google’s closed-source model that powers Google.com & OpenAI’s models that power ChatGPT all work equally well?
Computer scientists have been challenged distinguishing the relative performance of these models with many different tests. Users will be hard-pressed to do better.
At that point, the value in the model layer should collapse. If a freely available open-source model is just as good as a paid one, why not use the free one? And if a smaller, less expensive to operate open-source model is nearly as good, why not use that one?
The rapid growth of AI has fueled a surge of interest in the models themselves. But pretty quickly, the infrastructure layer should commoditize, just as it did in the cloud where three vendors command 65% market share : Amazon Web Services, Azure, & Google Cloud Platform.
The applications & the developer tooling around the massive AI commodity brokers is the next phase of development - where product differentiation & distribution differentiate rather than brilliant, raw technical advances.2
1 MMLU measures 57 different tasks including math, history, computer science & other topics. It’s one measure of many & it’s not perfect - like any benchmark. There are others including the Elo system. Here’s an overview of the differences.. Each benchmark grades the model on a different spectrum : bias, mathematical reasoning are two other examples.