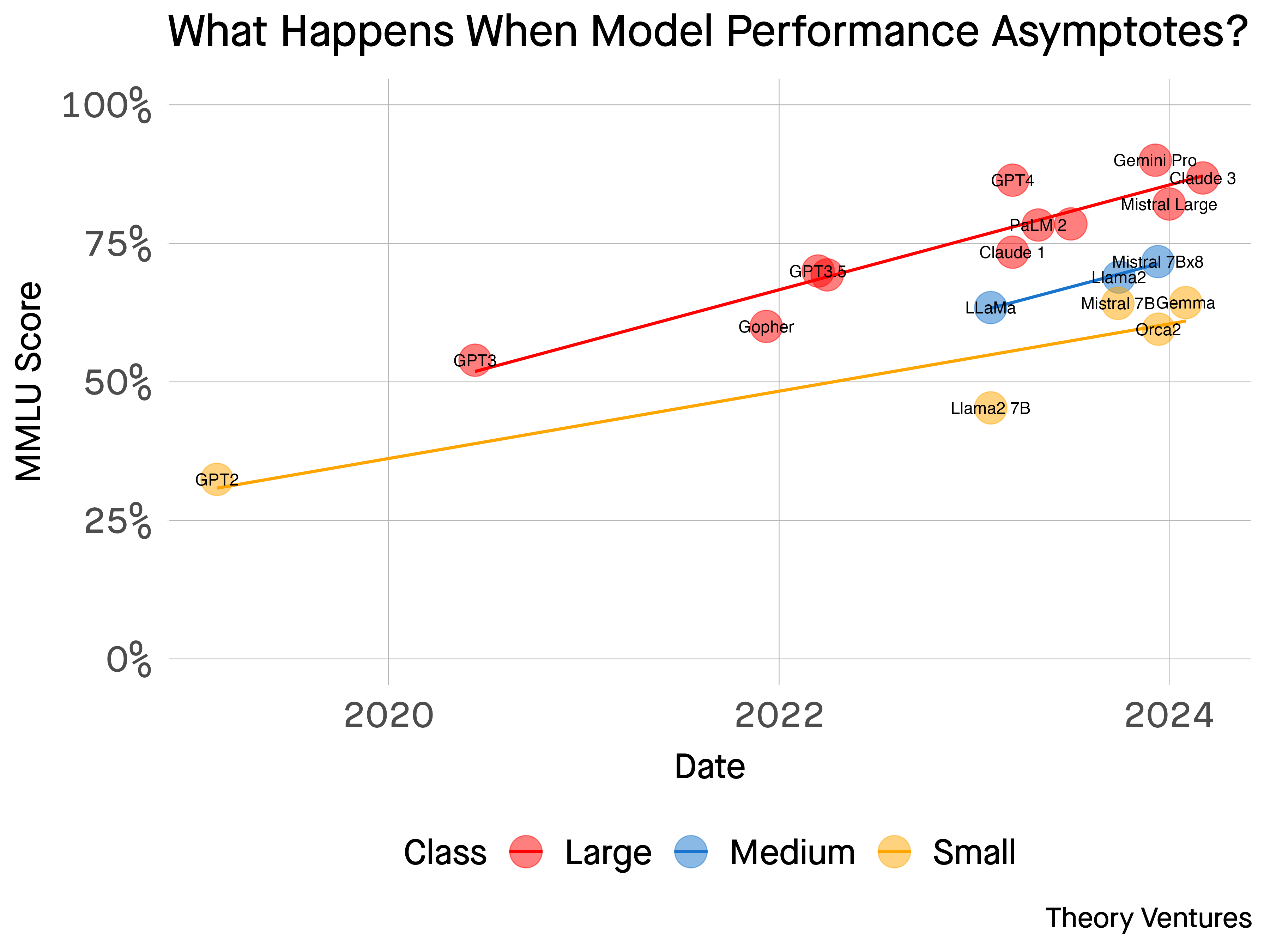
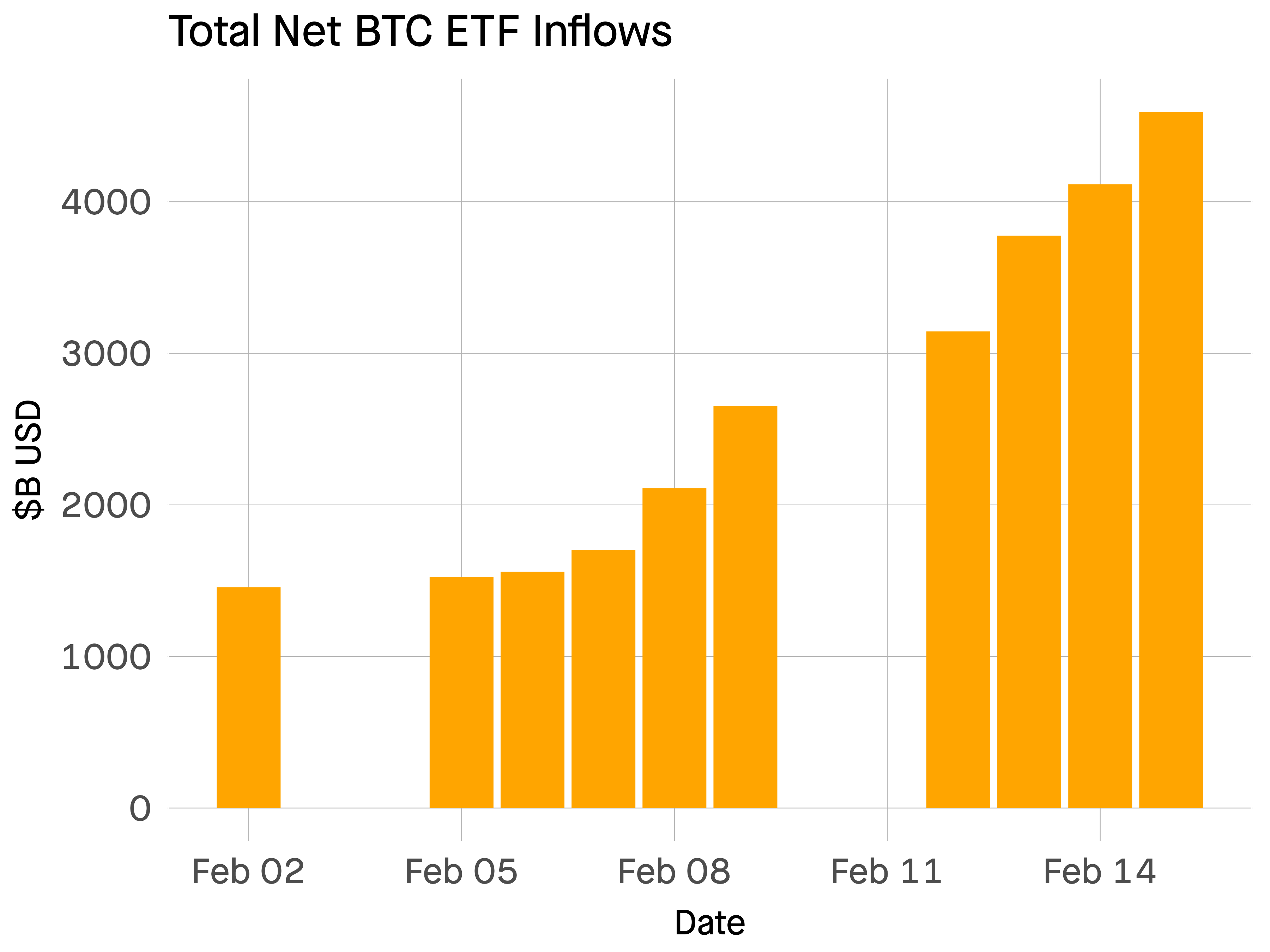
Looking into the Future of BI With Colin Zima

On March 15th at 9:30 Pacific time, Office Hours will host Colin Zima, CEO of Omni Analytics.
Colin is no stranger to business intelligence & data analysis. He worked on search quality at Google, founded a dynamic pricing company for the restaurant industry, then ran data at a HotelTonight before becoming Chief Analytics Officer at Looker through its acquisition by Google.